* 해당 포스팅은 김영한님의 자바 고급편 강의를 학습 후 정리한 포스팅 입니다.
Intro
안녕하세요 이번에 스레드 포스팅 시리즈를 쭉 이어오고 있는데
원래는 맨 처음 프로세스와 스레드의 차이 부터 시작하면서 쭉 진행할려고 했는데
그렇게 하기엔 스레드 관련 포스팅을 하기엔 내용이 너무 방대하고
Lock 인터페이스를 활용해서 객체를 구현할 일도 거의 없구요
이미 자바에서 잘 만들어진 Executor 객체를 사용할 텐데
우선은 실무에서 바로 사용할 수 있는 개념과 코드 예제를 설명하고
그 다음 포스팅을 차근 차근 풀어나가도록 할려고 노선을 변경했습니다.
그래서 갑자기 포스팅이 쭉 이어오다가 뜬금없이 Excutor 개념이 나왔는데
앞으로 계속 작성은 할테니깐요 쭉 지켜봐주시면 정말 감사하겠습니다!!
스레드를 직접 사용할 때의 문제점
1. 스레드 생성 시간으로 인한 성능문제
2. 스레드 관리문제
3. Runnable 인터페이스의 불편함
1. 스레드 생성 비용으로 인한 성능 문제
스레드를 사용하려면 먼저 스레드를 사용하는건 당연한건데
문제는 스레드를 직접 생성하는 작업은 정말 무겁습니다 그 이유는 아래와 같은데
1. 메모리 할당 : 스레드는 각자의 호출 스택이 필요하고 그만큼 메모리 공간을 필요합니다.
2. 운영체제 자원 사용: 스레드를 생성하는 작업은 운영체제 커널 수준에서 이루어지고 , 시슷템 콜을 통해 처리됩니다,, 결국 cpu, 메로리 자원을 사용하는 작업이죠
3. 운영체제 스케줄러 설정: 새로은 스레드는 운영체제의 스케줄러 스레드를 관리하고 실행 순서를 조정해야하는데 스케줄링 알고리즘에 따라 추가적인 오버헤드가 발생할 수 있습니다.
2. 스레드 관리문제
서버의 cpu, 메모리 자원은 한정되어있고 무한하게 생성할 수 없습니다
예를 들자면 어떤 선착순 할인 이벤트를 진행하게 되었는데 갑자기 몰린 트래픽을 감당하지 못해서 100개 정도 스레드로 충분했던 것이
갑자기 10000개의 스레드가 필요한 상황이 된다면 cpu, 메모리 자원이 버티지 못합니다.
이런 문제를 해결하려면 우리 시스템이 버틸 수 있는, 최대 스레드의 수 까지만 스레드를 생성할 수 있게 관리해야합니다.
3. Runnable 인터페이스의 불편함
Runnable 인터페이스는 의 함수 run() 의 경우 반환값을 가지지 않고 실행 결과를 얻기 위해서는 별도의 메커니즘을 사용해야합니다, 쉽게 이야기 해서 스레드의 실행결과를 직접 받을 수 없습니다. (벌써 불편...)
예외처리 문제 존재
run() 메서드는 또한 체크 예외를 던질 수 없는데 결국 체크예외도 메서드 내부에서 처리해야합니다.
4. 위 문제를 해결 방법은?
바로 스레드 풀 이라는 개념이 나오는데요
지금까지 설명한 1, 2번 문제를 해결하려면 스레드를 생성하고 관리하는 Poolㅇ이 필요합니다.

앞에서 설명한것 처럼 스레드를 그때 그때 생성하는것은 너무 무거운 작업 이므로 미리 여러개의 스레드를 생성한 뒤에
Pool 에 관리해서 재사용하게 되었습니다

특정 작업이 들어오면 이미 생성된 스레드를 하나 조회한뒤에 해당 스레드로 작업을 처리합니다.

그리고 작업이 완료되었다면 다시 해당 스레드를 반환하는거죠
사실 스레드풀이 대단한건 아니고 단순히 컬렉션에 스레드를 보관하고 재사용할 수 있게 해주면 되는데
문제는 스레드 풀에 있는 스레드는 처리할 작업이 없으면 대기 상태로 관리하고, 작업요청이 오면 다시 Runnable 상태로 변경하고
신경써야 할 문제가 너무 많죠 따라서 위 문제를 신경쓰지 않고 편안하게 사용할 수 있는 Excutor 프레임워크를 사용하는것이죠
Excutor 프레임워크 소개
자바의 Excutor 프레임워크는 멀티스레딩 및 병렬 처리를 돕는 기능 모음집입니다, 이를 사용함으로써 스레드 풀 관리를 효율적으로 처리해서 직접 스레드를 생성하고 관리하는 복잡함을 줄여주는 것이죠
1. Executor 인터페이스
Executor 인터페이스
package java.util.concurrent;
public interface Executor {
void execute(Runnable command);
}단순하게 작업 실행 인터페이스 execute(Runnable command) 메서드 하나를 가지고 있습니다.
2. ExcutorService 주요 메서드
public interface ExecutorService extends Executor, AutoCloseable {
<T> Future<T> submit(Callable<T> task);
@Override
default void close() {
// close 메서드 구현
...
}
// 기타 메서드들...
}Excutor 인터페이스를 확장해서 작업 제출과 제어 기능을 추가로 제공합니다.
주요 메서드로는 submit(), close()가 존재합니다.
더 많은 기능이 있지만 나중에 차차 설명드리겠습니다
Executor 프레임워크를 사용할 때는 대부분 이 인터페이스를 사용하고 있다는 점을 알고 계시면 좋을것 같습니다.
3. Excutor 주요 구현제 ThreadPoolExecutor
ThreadPoolExecutor 객체를 사용해서 간단한 예제를 통해 내부 동작을 한번 보여드리겠습니다.
간단하게 1초간 대기하는 작업을 만들어보겠습니다.
package thread.executor;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class RunnableTask implements Runnable {
private final String name;
private int sleepMs = 1000;
// 생성자 - 기본 sleep 시간
public RunnableTask(String name) {
this.name = name;
}
// 생성자 - 사용자 정의 sleep 시간
public RunnableTask(String name, int sleepMs) {
this.name = name;
this.sleepMs = sleepMs;
}
@Override
public void run() {
log(name + " 시작");
sleep(sleepMs); // 작업 시간 시뮬레이션
log(name + " 완료");
}
}
1초간 대기하는 작업을 구현했으니 이제는 해당 작업을 담당하는 서비스를 작성하여 작업을 처리하는 코드를 작성하겠습니다.
package thread.executor;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.LinkedBlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
import static thread.executor.ExecutorUtils.*;
import static util.MyLogger.log;
import static util.ThreadUtils.sleep;
public class ExecutorBasicMain {
public static void main(String[] args) throws InterruptedException {
ExecutorService es = new ThreadPoolExecutor(
2, 2, 0,
TimeUnit.MILLISECONDS, new LinkedBlockingQueue<>()
);
log("== 초기 상태 ==");
printState(es);
es.execute(new RunnableTask("taskA"));
es.execute(new RunnableTask("taskB"));
es.execute(new RunnableTask("taskC"));
es.execute(new RunnableTask("taskD"));
log("== 작업 수행 중 ==");
printState(es);
sleep(3000);
log("== 작업 수행 완료 ==");
printState(es);
es.close();
log("== shutdown 완료 ==");
printState(es);
}
}
이제 ThreadPoolExecutor 내부를 보여드리겠습니다.

이제 크게 2가지로 구성되어있는데
스레드 풀: 스레드를 관리하고
BlockingQueue: 작업을 보관합니다
생산자가 es.execute 를 호출하면 , RunnableTask 인스턴스가 BlockingQueue에 보관됩니다.
그렇담 소비자에서 (풀에 담겨있는 스레드)는 이후에 소비자 중에 하나가 BlockingQueue 에 담긴 작업을 받아서 처리하는 구조입니다.

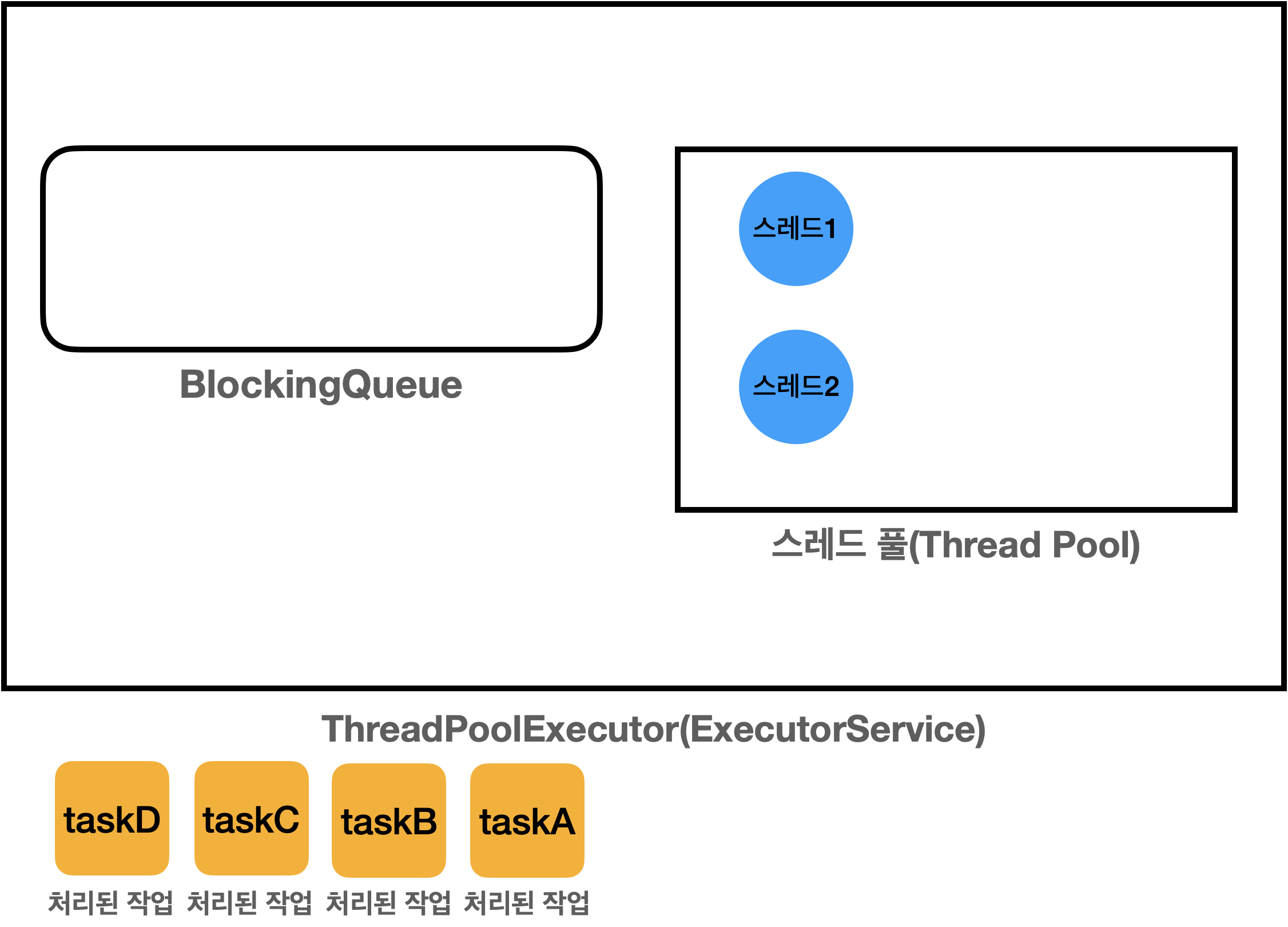
위 코드를 실행하면 초기상태에입니다
ThreadPoolExecutor를 생성한 시점에는 스레드 풀에 스레드를 미리 만들어주지 않습니다
위에 제가 미리 만들어둔다는 표현을 했는데 스레드 풀 전략이 있습니다. 그에 따라 미리 만둘지 아니면 생성시점에 만들지 달라집니다
스레드 풀 전략에 대해서도 설명드리겠습니다 우선은 현재 코드에서는 초기상태에는 비여져있다고 보시면 됩니다.

main 스레드에서 es.execute 메서드를 호출합니다.
그렇다면 작업들이 BlockingQueue 에 들어오고
작업이 들어올때 마다 corePoolSize의 크기까지 스레드를 생성합니다.

이제 스레드는 해당 작업들을 처리합니다 그림에서는 이해하기 쉽게 위해서 마치 풀에서 스레드를 꺼내서 작업하는것 같지만 실제로는 그저 풀안에서 상태만 변경된것입니다. Wating -> Runnable 로요
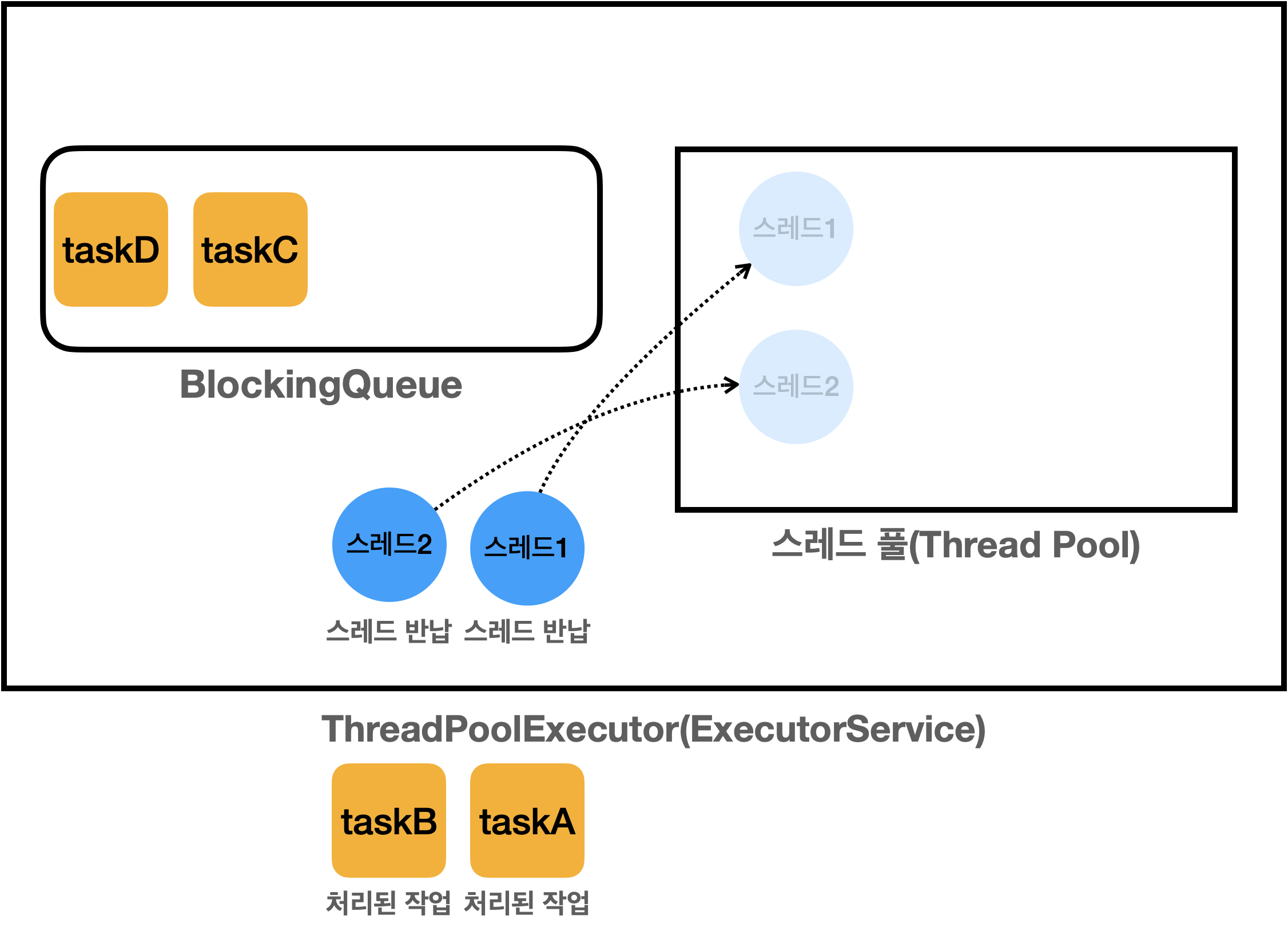
이제 작업이 완료되면 풀에 스레드를 반납하고 다시 Runnable -> Waiting 상태로 변경되고
다시 남은 2개의 task를 처리하기 위해서 다시 상태변경하여 BlockingQueue 에서 작업을 완료할때까지 반복합니다.
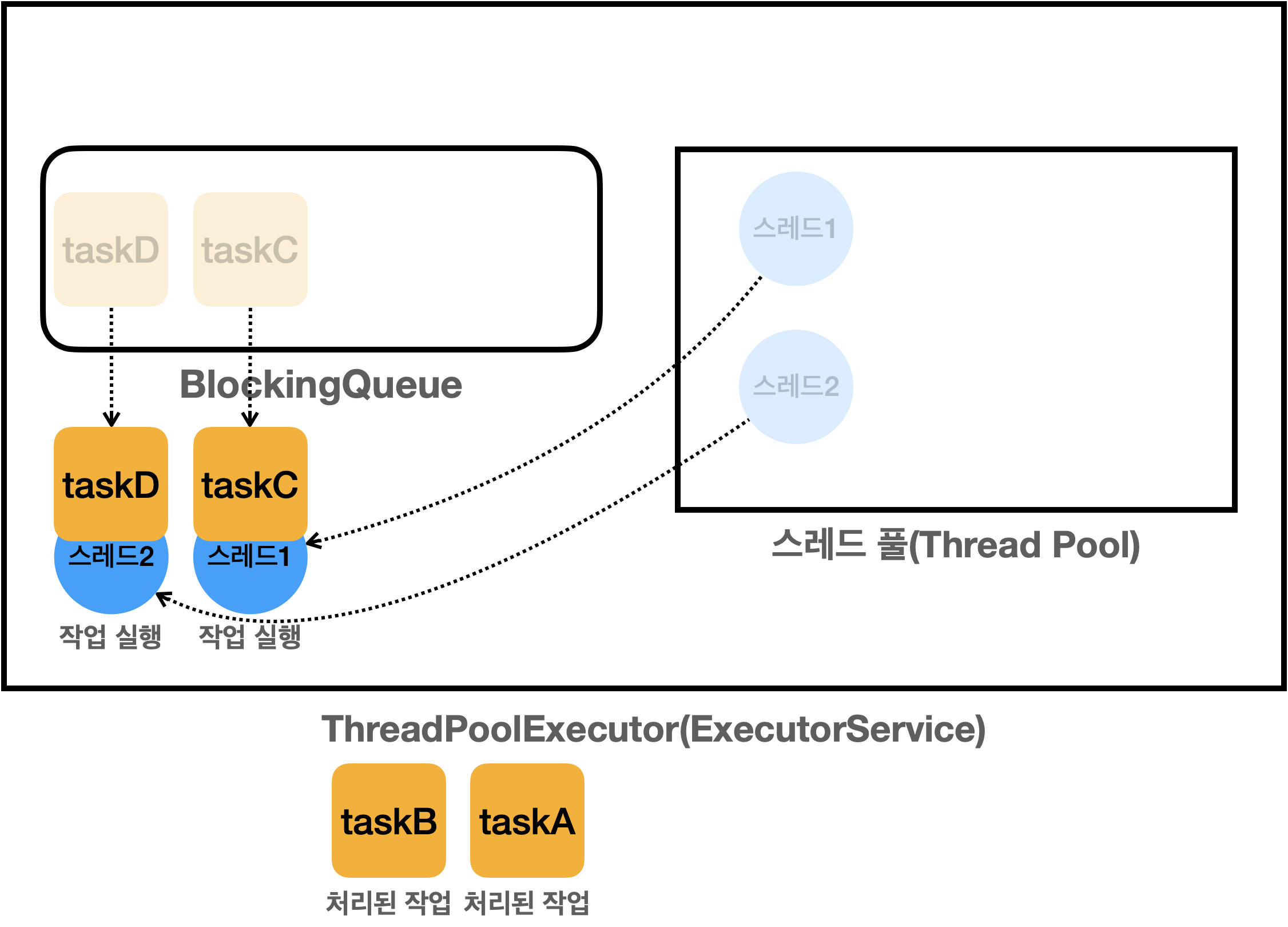
블락킹 큐에서 꺼내서 작업을 처리하고
다시 스레드는 Runnable -> Waiting 상태로 변경되고 대기합니다.

마지막으로 close() 메서드를 호출하여 남은 자원을 정리하고 풀에 대기하는 스레드도 함께 제거됩니다.
Runnable의 불편함
위에서 우리는 Runnable 인터페이스 너무 불편하다고 했는데
그 이유가 반환값도 없고 예외처리도 어렵다고 했습니다 (메서드 내부에서 예외를 처리해줘야 하니깐요..)
그래서 다음 포스팅에는 Future 객체에 대해서 알아볼것입니다. 해당 포스팅에 전부 해놓으면 스크롤도 너무 길어서 읽을 사람이 있으려나 싶네요..
이로써 오늘 포스팅
Executor 인터페이스 ExecutorService를 알아보았고
내부 동작 방식까지 알아보았습니다
다음 포스팅은 위에 말한 Future 객체를 통해 기존의 Runnable 인터페이스의 run() 메서드의 불편함을 어떻게 해결했는지
그리고 어떻게 Executor를 활용해서 사용할지 정리하는 시간을 가지겠습니다
읽어주셔서 감사합니다!
'Java' 카테고리의 다른 글
| Socket을 활용한 채팅 네트워크 프로그램 객체지향을 곁들인... (0) | 2025.03.16 |
|---|---|
| Java 리플랙션<Reflection> (2) | 2025.02.21 |
| [Java]ReentrantLock (9) | 2024.09.18 |
| 자바의 고오급 동기화 concurrent.Lock (7) | 2024.09.14 |
| Java 프로세스와 스레드 (4) | 2024.08.30 |